Imagine you have a Linux kernel image for an Android phone, but you don t have the corresponding source, nor do you have the corresponding kernel headers. Imagine that kernel has module support (fortunately), and that you d like to build a module for it to load. There are several good reasons why you can t just build a new kernel from source and be done with it (e.g. the resulting kernel lacks support for important hardware, like the LCD or touchscreen). With the ever-changing Linux kernel ABI, and the lack of source and headers, you d think you re pretty much in a dead-end.
As a matter of fact, if you build a kernel module against different kernel headers, the module will fail to load with errors depending on how different they are. It can complain about bad signatures, bad version or other different things.
But more on that later.
Configuring a kernel
The first thing is to find a kernel source for something close enough to the kernel image you have. That s probably the trickiest part with getting a proper configuration. Start from the version number you can read from
/proc/version. If, like me, you re targeting an Android device, try Android kernels from Code Aurora, Linaro, Cyanogen or Android, whichever is closest to what is in your phone. In my case, it was msm-3.0 kernel. Note you don t necessarily need the exact same version. A minor version difference is still likely to work. I ve been using a 3.0.21 source, which the kernel image was 3.0.8. Don t however try e.g. using a 3.1 kernel source when the kernel you have is 3.0.x.
If the kernel image you have is kind enough to provide a
/proc/config.gz file, you can start from there, otherwise, you can try starting from the default configuration, but you need to be extra careful, then (although I won t detail using the default configuration because I was fortunate enough that I didn t have to, there will be some details further below as to why a proper configuration is important).
Assuming
arm-eabi-gcc is in your
PATH, and that you have a shell opened in the kernel source directory, you need to start by configuring the kernel and install headers and scripts:
$ mkdir build
$ gunzip -c config.gz > build/.config # Or whatever you need to prepare a .config
$ make silentoldconfig prepare headers_install scripts ARCH=arm CROSS_COMPILE=arm-eabi- O=build KERNELRELEASE= adb shell uname -r
The
silentoldconfig target is likely to ask you some questions about whether you want to enable some things. You may want to opt for the default, but that may also not work properly.
You may use something different for
KERNELRELEASE, but it needs to match the exact kernel version you ll be loading the module from.
A simple module
To create a dummy module, you need to create two files: a source file, and a
Makefile.
Place the following content in a
hello.c file, in some dedicated directory:
#include <linux/module.h> /* Needed by all modules */
#include <linux/kernel.h> /* Needed for KERN_INFO */
#include <linux/init.h> /* Needed for the macros */
static int __init hello_start(void)
printk(KERN_INFO "Hello world\n");
return 0;
static void __exit hello_end(void)
printk(KERN_INFO "Goodbye world\n");
module_init(hello_start);
module_exit(hello_end);
Place the following content in a
Makefile under the same directory:
obj-m = hello.o
Building such a module is pretty straightforward, but at this point, it won t work yet. Let me enter some details first.
The building of a module
When you normally build the above module, the kernel build system creates a
hello.mod.c file, which content can create several kind of problems:
MODULE_INFO(vermagic, VERMAGIC_STRING);
VERMAGIC_STRING is derived from the
UTS_RELEASE macro defined in
include/generated/utsrelease.h, generated by the kernel build system. By default, its value is derived from the actual kernel version, and git repository status. This is what setting
KERNELRELEASE when configuring the kernel above modified. If
VERMAGIC_STRING doesn t match the kernel version, loading the module will lead to the following kind of message in
dmesg:
hello: version magic '3.0.21-perf-ge728813-00399-gd5fa0c9' should be '3.0.8-perf'
Then, there s the module definition.
struct module __this_module
__attribute__((section(".gnu.linkonce.this_module"))) =
.name = KBUILD_MODNAME,
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
.arch = MODULE_ARCH_INIT,
;
In itself, this looks benign, but the
struct module, defined in
include/linux/module.h comes with an unpleasant surprise:
struct module
(...)
#ifdef CONFIG_UNUSED_SYMBOLS
(...)
#endif
(...)
/* Startup function. */
int (*init)(void);
(...)
#ifdef CONFIG_GENERIC_BUG
(...)
#endif
#ifdef CONFIG_KALLSYMS
(...)
#endif
(...)
(... plenty more ifdefs ...)
#ifdef CONFIG_MODULE_UNLOAD
(...)
/* Destruction function. */
void (*exit)(void);
(...)
#endif
(...)
This means for the
init pointer to be at the right place,
CONFIG_UNUSED_SYMBOLS needs to be defined according to what the kernel image uses. And for the
exit pointer, it s
CONFIG_GENERIC_BUG,
CONFIG_KALLSYMS,
CONFIG_SMP,
CONFIG_TRACEPOINTS,
CONFIG_JUMP_LABEL,
CONFIG_TRACING,
CONFIG_EVENT_TRACING,
CONFIG_FTRACE_MCOUNT_RECORD and
CONFIG_MODULE_UNLOAD.
Start to understand why you re supposed to use the exact kernel headers matching your kernel?
Then, the symbol version definitions:
static const struct modversion_info ____versions[]
__used
__attribute__((section("__versions"))) =
0xsomehex, "module_layout" ,
0xsomehex, "__aeabi_unwind_cpp_pr0" ,
0xsomehex, "printk" ,
;
These come from the
Module.symvers file you get with your kernel headers. Each entry represents a symbol the module requires, and what signature it is expected to have. The first symbol,
module_layout, varies depending on what
struct module looks like, i.e. depending on which of the config options mentioned above are enabled. The second,
__aeabi_unwind_cpp_pr0, is an ARM ABI specific function, and the last, is for our
printk function calls.
The signature for each function symbol may vary depending on the kernel code for that function, and the compiler used to compile the kernel. This means that if you have a kernel you built from source, modules built for that kernel, and rebuild the kernel after modifying e.g. the
printk function, even in a compatible way, the modules you built initially won t load with the new kernel.
So, if we were to build a kernel from the hopefully close enough source code, with the hopefully close enough configuration, chances are we wouldn t get the same signatures as the binary kernel we have, and it would complain as follows, when loading our module:
hello: disagrees about version of symbol symbol_name
Which means we need a proper
Module.symvers corresponding to the binary kernel, which, at the moment, we don t have.
Inspecting the kernel
Conveniently, since the kernel has to do these verifications when loading modules, it actually contains a list of the symbols it exports, and the corresponding signatures. When the kernel loads a module, it goes through all the symbols the module requires, in order to find them in its own symbol table (or other modules symbol table when the module uses symbols from other modules), and check the corresponding signature.
The kernel uses the following function to search in its symbol table (in
kernel/module.c):
bool each_symbol_section(bool (*fn)(const struct symsearch *arr,
struct module *owner,
void *data),
void *data)
struct module *mod;
static const struct symsearch arr[] =
__start___ksymtab, __stop___ksymtab, __start___kcrctab,
NOT_GPL_ONLY, false ,
__start___ksymtab_gpl, __stop___ksymtab_gpl,
__start___kcrctab_gpl,
GPL_ONLY, false ,
__start___ksymtab_gpl_future, __stop___ksymtab_gpl_future,
__start___kcrctab_gpl_future,
WILL_BE_GPL_ONLY, false ,
#ifdef CONFIG_UNUSED_SYMBOLS
__start___ksymtab_unused, __stop___ksymtab_unused,
__start___kcrctab_unused,
NOT_GPL_ONLY, true ,
__start___ksymtab_unused_gpl, __stop___ksymtab_unused_gpl,
__start___kcrctab_unused_gpl,
GPL_ONLY, true ,
#endif
;
if (each_symbol_in_section(arr, ARRAY_SIZE(arr), NULL, fn, data))
return true;
(...)
The
struct used in this function is defined in
include/linux/module.h as follows:
struct symsearch
const struct kernel_symbol *start, *stop;
const unsigned long *crcs;
enum
NOT_GPL_ONLY,
GPL_ONLY,
WILL_BE_GPL_ONLY,
licence;
bool unused;
;
Note: this kernel code hasn t changed significantly in the past four years.
What we have above is three (or five, when
CONFIG_UNUSED_SYMBOLS is defined) entries, each of which contains the start of a symbol table, the end of that symbol table, the start of the corresponding signature table, and two flags.
The data is static and constant, which means it will appear as is in the kernel binary. By scanning the kernel for three consecutive sequences of three pointers within the kernel address space followed by two integers with the values from the definitions in
each_symbol_section, we can deduce the location of the symbol and signature tables, and regenerate a
Module.symvers from the kernel binary.
Unfortunately, most kernels these days are compressed (zImage), so a simple search is not possible. A compressed kernel is actually a small bootstrap binary followed by a compressed stream. It is possible to scan the kernel zImage to look for the compressed stream, and decompress it from there.
I wrote a script to do
decompression and extraction of the symbols info automatically. It should work on any recent kernel, provided it is not relocatable and you know the base address where it is loaded. It takes options for the number of bits and endianness of the architecture, but defaults to values suitable for ARM. The base address, however, always needs to be provided. It can be found, on ARM kernels, in
dmesg:
$ adb shell dmesg grep "\.init"
<5>[01-01 00:00:00.000] [0: swapper] .init : 0xc0008000 - 0xc0037000 ( 188 kB)
The base address in the example above is
0xc0008000.
If like me you re interested in loading the module on an Android device, then what you have as a binary kernel is probably a complete boot image. A boot image contains other things besides the kernel, so you can t use it directly with the script. Except if the kernel in that boot image is compressed, in which case the part of the script that looks for the compressed image will find it anyways.
If the kernel is not compressed, you can use the
unbootimg program as outlined in this
old post of mine to get the kernel image out of your boot image. Once you have the kernel image, the script can be invoked as follows:
$ python extract-symvers.py -B 0xc0008000 kernel-filename > Module.symvers
Symbols and signature info could also be extracted from binary modules, but I was not interested in that information so the script doesn t handle that.
Building our module
Now that we have a proper
Module.symvers for the kernel we want to load our module in, we can finally build the module:
(again, assuming
arm-eabi-gcc is in your
PATH, and that you have a shell opened in the kernel source directory)
$ cp /path/to/Module.symvers build/
$ make M=/path/to/module/source ARCH=arm CROSS_COMPILE=arm-eabi- O=build modules
And that s it. You can now copy the resulting
hello.ko onto the device and load it.
and enjoy
$ adb shell
# insmod hello.ko
# dmesg grep insmod
<6>[mm-dd hh:mm:ss.xxx] [id: insmod]Hello world
# lsmod
hello 586 0 - Live 0xbf008000 (P)
# rmmod hello
# dmesg grep rmmod
<6>[mm-dd hh:mm:ss.xxx] [id: rmmod]Goodbye world
 Debian has recently received a donation of 8 build machines from Marvell. The new machines come with Quad core MV78460 Armada XP CPU's, DDR3 DIMM slot so we can plug in more memory, and speedy sata ports. They replace the well served Marvell MV78200 based builders - ones that have been building debian armel since 2009. We are planning a more detailed announcement, but I'll provide a quick summary: The speed increase provided by MV78460 can viewed by comparing build times on selected builds since early april:
Debian has recently received a donation of 8 build machines from Marvell. The new machines come with Quad core MV78460 Armada XP CPU's, DDR3 DIMM slot so we can plug in more memory, and speedy sata ports. They replace the well served Marvell MV78200 based builders - ones that have been building debian armel since 2009. We are planning a more detailed announcement, but I'll provide a quick summary: The speed increase provided by MV78460 can viewed by comparing build times on selected builds since early april:  Qemu build times. We can now build Qemu in 2h instead of 16h -8x faster than before! Certainly a substantial improvement, so impressive kit from Marvell! But not all packages gain this amount of speedup:
Qemu build times. We can now build Qemu in 2h instead of 16h -8x faster than before! Certainly a substantial improvement, so impressive kit from Marvell! But not all packages gain this amount of speedup:  webkitgtk build times. This example, webkitgtk, builds barely 3x faster. The explanation is found from debian/rules of webkitgkt:
webkitgtk build times. This example, webkitgtk, builds barely 3x faster. The explanation is found from debian/rules of webkitgkt: 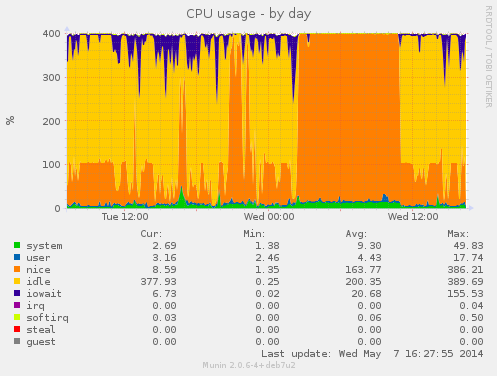 During this buildd cpu usage graph, we see most time only one CPU is consumed. So for fast package build times.. make sure your packages supports parallel building. For developers, abel.debian.org is porter machine with Armada XP. It has schroot's for both armel and armhf. set "DEB_BUILD_OPTIONS=parallel=4" and off you go. Finally I'd like to thank Thomas Petazzoni, Maen Suleiman, Hector Oron, Steve McIntyre, Adam Conrad and Jon Ward for making the upgrade happen. Meanwhile, we have unrelated trouble - a bunch of disks have broken within a few days apart. I take the warranty just run out... [1] only from Linux's point of view. - mv78200 has actually 2 cores, just not SMP or coherent. You could run an RTOS on the other core while you run Linux on the other.
During this buildd cpu usage graph, we see most time only one CPU is consumed. So for fast package build times.. make sure your packages supports parallel building. For developers, abel.debian.org is porter machine with Armada XP. It has schroot's for both armel and armhf. set "DEB_BUILD_OPTIONS=parallel=4" and off you go. Finally I'd like to thank Thomas Petazzoni, Maen Suleiman, Hector Oron, Steve McIntyre, Adam Conrad and Jon Ward for making the upgrade happen. Meanwhile, we have unrelated trouble - a bunch of disks have broken within a few days apart. I take the warranty just run out... [1] only from Linux's point of view. - mv78200 has actually 2 cores, just not SMP or coherent. You could run an RTOS on the other core while you run Linux on the other.
 First step will be getting a NetBSD ISO image for installation
purpose. It can be downloaded from
First step will be getting a NetBSD ISO image for installation
purpose. It can be downloaded from  The
The 







 Having
Having  Migrating a Debian installation between architectures has always been difficult. The recommended way to
crossgrade an i386 Debian to amd64 Debian was to reinstall the system, move over data and configuration.
For the more brave, in-place crossgrades usually involved chroots, rescue CDs, a lot of ar p tar xf - data.tar.gz and
luck.
I have never been brave when it comes to system administration, have done a lot of architecture migrations with
reinstallation, and have always taken the opportunity to clear out the contamination that accumulates itself when a
system is running for a long time. I would even recommend doing this to most people even now. However, I have a few very
ugly systems in place that are still on i386 because I didn t dare going the reinstallation path.
Doing in-place crossgrades has become a lot easier since wheezy s release, since once now can have both i386 and
amd64 libraries installed in parallel, which allows to replace foo:i386 with foo:amd64 without influencing the other
parts of the system. The process is still full of pitfalls:
Migrating a Debian installation between architectures has always been difficult. The recommended way to
crossgrade an i386 Debian to amd64 Debian was to reinstall the system, move over data and configuration.
For the more brave, in-place crossgrades usually involved chroots, rescue CDs, a lot of ar p tar xf - data.tar.gz and
luck.
I have never been brave when it comes to system administration, have done a lot of architecture migrations with
reinstallation, and have always taken the opportunity to clear out the contamination that accumulates itself when a
system is running for a long time. I would even recommend doing this to most people even now. However, I have a few very
ugly systems in place that are still on i386 because I didn t dare going the reinstallation path.
Doing in-place crossgrades has become a lot easier since wheezy s release, since once now can have both i386 and
amd64 libraries installed in parallel, which allows to replace foo:i386 with foo:amd64 without influencing the other
parts of the system. The process is still full of pitfalls:

 While almost everyone has already worked with cryptographic signatures,
they are usually only used as black boxes, without taking a closer look.
This article intends to shed some lights behind the scenes.
Let's take a look at some signature. In ascii-armoured form or behind
a clearsigned message one often does only see something like this:
While almost everyone has already worked with cryptographic signatures,
they are usually only used as black boxes, without taking a closer look.
This article intends to shed some lights behind the scenes.
Let's take a look at some signature. In ascii-armoured form or behind
a clearsigned message one often does only see something like this:
 Here is the short version: to get better performance on your
Here is the short version: to get better performance on your  The most important plot is the top one. The blue line is the attempted
number of transactions per second (
The most important plot is the top one. The blue line is the attempted
number of transactions per second ( It is able to get the same performance as stud (763
It is able to get the same performance as stud (763 
 As you can see in the plot above, only stud is able to scale
properly. stunnel is not able to take advantage of the cores and its
performances are worse than with a single core. I think this may be
due to its threaded model and the fact that the userland for this
32bit system is a bit old. nginx is able to achieve the same
As you can see in the plot above, only stud is able to scale
properly. stunnel is not able to take advantage of the cores and its
performances are worse than with a single core. I think this may be
due to its threaded model and the fact that the userland for this
32bit system is a bit old. nginx is able to achieve the same 

 This plot also explains why stud performances fall after the
maximum: because of the failed transactions, the session cache is not
as efficient. This phenomenon does not exist when session reuse is not enabled.
This plot also explains why stud performances fall after the
maximum: because of the failed transactions, the session cache is not
as efficient. This phenomenon does not exist when session reuse is not enabled.
 The major upcoming configuration change in Linux 2.6.39 is to get
rid of the '686' flavour. This may be surprising, because it's the
most widely used flavour of the 4 we have a present:
The major upcoming configuration change in Linux 2.6.39 is to get
rid of the '686' flavour. This may be surprising, because it's the
most widely used flavour of the 4 we have a present:
 In this post I'll describe the changes made to the kernel and some of the
Squeeze packages for the Freaky Wall.
The plan is to submit whishlist bugs to the BTS on the hope of having all what
is needed for this project available on Debian after the Squeeze release, as
my feeling is that a freeze is not the right time to push this changes... ;)
I'm giving access here to all the changes made to the source packages, but if
anyone wants the binary packages (amd64 only) send me an email and I'll give
you the URL of an apt repository that contains all the modified packages (it's
the one at work, that contains other modified packages) or, if there is
interest, I can put them on people.debian.org.
Kernel
To be able to build the firewall we need a kFreeBSD kernel with some options
not compiled on the version distributed with Debian.
To compile the kernel I've followed the procedure described on the following
debian-bsd mailing list post:
In this post I'll describe the changes made to the kernel and some of the
Squeeze packages for the Freaky Wall.
The plan is to submit whishlist bugs to the BTS on the hope of having all what
is needed for this project available on Debian after the Squeeze release, as
my feeling is that a freeze is not the right time to push this changes... ;)
I'm giving access here to all the changes made to the source packages, but if
anyone wants the binary packages (amd64 only) send me an email and I'll give
you the URL of an apt repository that contains all the modified packages (it's
the one at work, that contains other modified packages) or, if there is
interest, I can put them on people.debian.org.
Kernel
To be able to build the firewall we need a kFreeBSD kernel with some options
not compiled on the version distributed with Debian.
To compile the kernel I've followed the procedure described on the following
debian-bsd mailing list post:
 I blogged back in August about my
I blogged back in August about my {kind=link}